PySpark seemingly allows Python code to run on Apache Spark - a JVM based computing framework. How is this possible? I recently needed to answer this question and although the PySpark API itself is well documented, there is little in-depth information on its implementation. This article contains my findings from diving into the Spark source code to find out what’s really going.
Spark vs PySpark
For the purposes of this article, Spark refers to the Spark JVM implementation as a whole. This includes the Spark Core execution engine as well as the higher level APIs that utilise it; Spark SQL, Spark Streaming etc. PySpark refers to the Python API for Spark.
This distinction is important to understand the motivation for this article:
Spark is a system that runs on the JVM (usually) across multiple machines. PySpark enables direct control of and interaction with this system via Python.
How does this work? Take a look at this visual1 “TL;DR” and then read on to find out what it all means:
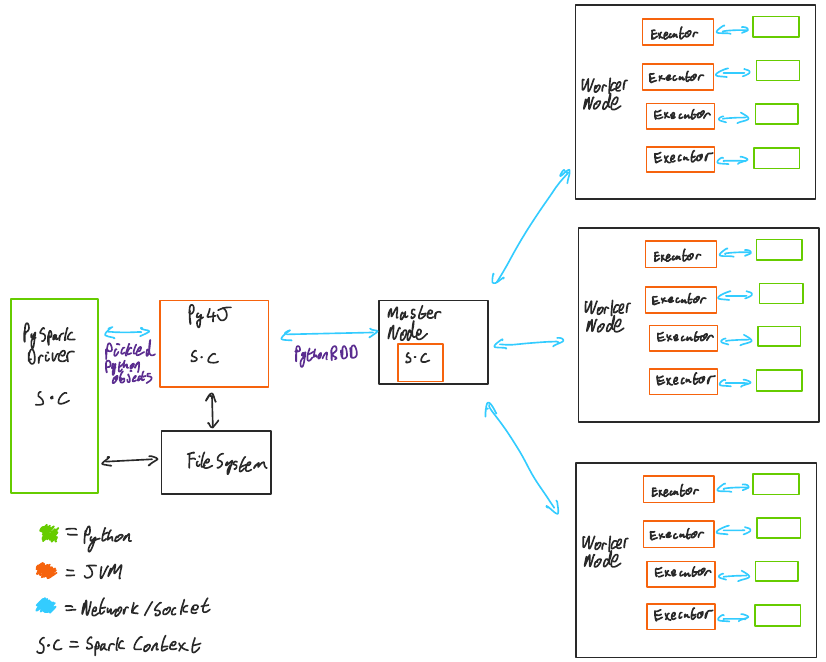
PySpark Execution Model
The high level separation between Python and the JVM is that:
- Data processing is handled by Python processes.
- Data persistence and transfer is handled by Spark JVM processes.
The Python driver program communicates with a local JVM running Spark via Py4J2. Spark workers spawn Python processes, communicating results via TCP sockets.
SparkContext and Py4J
A PySpark driver program begins by instantiating a SparkContext; either
directly or indirectly using a SparkSession:
# Direct
from pyspark import SparkContext
sc = SparkContext(
master="spark-cluster.steadbytes.com", appName="yet_another_word_count"
)
# Indirect - SparkSession manages an underlying SparkContext
from pyspark.sql import SparkSession
spark = (
SparkSession.builder.master("spark-cluster.steadbytes.com")
.appName("yet_another_word_count")
.getOrCreate()
)
In the driver program, pyspark.SparkContext executes spark-submit in a subprocess (yes, that spark-submit) in to initialise a local Spark JVM process:
# ...
script = "./bin/spark-submit.cmd" if on_windows else "./bin/spark-submit"
command = [os.path.join(SPARK_HOME, script)]
# ...
proc = Popen(command, stdin=PIPE, preexec_fn=preexec_func, env=env)
# ...
Before executing spark-submit, a temporary file is created and it’s name is exported as an environment variable:
# ...
conn_info_dir = tempfile.mkdtemp()
try:
fd, conn_info_file = tempfile.mkstemp(dir=conn_info_dir)
env = dict(os.environ)
env["_PYSPARK_DRIVER_CONN_INFO_PATH"] = conn_info_file
# ...
Subsequently, spark-submit instantiates a PythonGatewayServer to initialise a Py4J server and write the Py4J server connection details to this file:
// ...
val gatewayServer: Py4JServer = new Py4JServer(sparkConf)
gatewayServer.start()
val boundPort: Int = gatewayServer.getListeningPort
// ...
val connectionInfoPath = new File(sys.env("_PYSPARK_DRIVER_CONN_INFO_PATH"))
val dos = new DataOutputStream(new FileOutputStream(tmpPath))
dos.writeInt(boundPort)
val secretBytes = gatewayServer.secret.getBytes(UTF_8)
dos.writeInt(secretBytes.length)
dos.write(secretBytes, 0, secretBytes.length)
dos.close()
// ...
The Python driver can then read the contents of the file to establish a Py4J gateway to enable communication between the Python driver and the local Spark JVM process:
# ...
with open(conn_info_file, "rb") as info:
gateway_port = read_int(info)
gateway_secret = UTF8Deserializer().loads(info)
# ...
Spark Workers and the PythonRDD
A Spark program defines a series of transformations/actions to be performed on some data:
lines = spark.read.text("/path/to/a/big/file.txt").rdd.map(lambda r: r[0])
words = lines.flatMap(lambda line: line.split(' '))
pairs = words.map(lambda word: (word, 1))
word_counts = pairs.reduceByKey(operator.add)
for (word, count) in word_counts.collect():
print(f"{word}: {count}")
Any functions passed as arguments to Spark RDD operations in the driver program (e.g. map, flatMap, reduceByKey in the above example) are serialised using cloudpickle.
These are then shipped to Spark worker machines by PythonRDD objects which spawn Python processes; serialised code is deserialised, executed and results are sent back to the PythonRDD in the JVM via a TCP socket3.
Summary
There are (as always) further details and intricacies involved in the execution of a PySpark program, however the above should be sufficient to at least understand where the code is running and how different components communicate.
-
I make no claims to being an artist; this is reaching the limit of my artistic skill. ↩︎
-
In depth discussion of how Py4J works is out of scope for this article; please refer to the documentation for further details. ↩︎
-
The implementation of the socket server itself is out of scope for this article, however I encourage the reader to take a look at the source if interested. ↩︎